正则表达式手册
1. 正则
什么是正则表达式
正则表达式是一种特殊的字符串模式,用于匹配一组字符串, 就好比用模具做产品, 而正则就是这个模具,定义一种规则去匹配符合规则的字符。通俗的讲就是一个筛子。
在线匹配工具
2. 基本用法
界定符
正则表达式的界定符可以使用 // , ## , ~~ , @@ 等等,默认采用 // .
元字符
\w: 匹配字母、数字、下划线\W: 任意一个非字母、数字、下划线的字符\d: 匹配任意一个十进制数字\D: 匹配一个非数字字符\s: 匹配任意一个空白字符, 空格、换行、回车、制表符、换页[\f\n\r\t\v]\S: 任意一个非空白字符\b: 匹配一个单词边界\B: 匹配非单词边界|: 选择字符,表示或者.: 表示除了换行符以外的所有字符[]: 字符组,表示一个集合\: 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,n匹配字符n。\n匹配一个换行符。序列\\匹配\而\(则匹配(.
[a-z] 匹配a-z中的任意一个字符.点字符 : 匹配除了回车换行符之外的任意字符-: 连字符, 表示一个范围, 只有在字符组[]内部,连字符才是元字符, 否则他就只能是普通的连字符号.即使在字符组内部,他也不一定就是元字符.如果连字符出现在字符组的开头, 它表示的就只是一个普通字符, 而不是一个范围. 同样的道理, 问号和点号通常被当做元字符处理, 但是在字符组中则不是如此(说明白一点就是[0-9A-Z_!.?]里面,真正的特殊字符就是有那两个连字符)
^ , $ 特殊符号的使用
^ 在 [] 中,表示除了, [^\d] , 表示除了数字之外的任意字符
^ 在 [] 外,表示起始的地方, $ 表示结束的地方。启用 Multiline 属性, ^ 也匹配 \n 或 \r 之后的位置, $ 也匹配 \n 或 \r 之前的位置
如: /^a.*\d$/ 只可以匹配已字符a开始,已数字结束的字符量词
{}形式- : 任意的数量,等价于
{0,} +: 至少一次,等价于{1,}?: 匹配 0 次或者 1 次, 元字符后面使用 ?,作为量词,表示限定字符数量为0或1.
如: you(r)?, 可以匹配you 或者是your非打印字符
| 代码语法 | 说明 | 十六进制表现 |
\a | Bell报警字符 | 0x07 |
\e | Escape | 0x1B |
\f | 分页 | 0x0C |
\n | 换行 | 0x0A |
\r | 回车 | 0x0D |
\t | 水平制表符,Tab | 0x09 |
\v | 垂直制表符 | 0x0B |
\b | 退格符/删除符, 在perl的表达式中 他匹配字符的边界,但是在字符组中匹配一个退格符 |
根据ECMA-262标准,JavaScript不支持 \a \e ,我们使用 \x07 \x1B 来替换,但是有些浏览器也是支持 \a \e 的
控制字符
匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符
7位元字符
一个小写的 \x 加上两个大写的16进制的字符匹配ASCII中的单字符.这里支持的内容参考 ASCII Code - The extended ASCII table
3. 默认模式和懒惰模式
懒惰模式(尽可能少的匹配)
当该字符紧跟在任何一个其他限制符 ( * , + , ? , {n} , {n,} , {n,m} ) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 oooo , o+? 将匹配单个 o ,而 o+ 将匹配所有 o 。
?: 匹配任意次,但尽可能少的匹配
如: a.*?b 匹配 babacb只会匹配到ab+?: 匹配一次或多次,但尽可能少的匹配
如: a.+?b 匹配babacb, 会匹配到abacb??: 匹配0次或1次,尽可能少的匹配
如: a.??b 匹配babacb, 会匹配到ab{n,m}?: 匹配n到m次,尽可能少的匹配
如:a{0,6}? 匹配 aaaaaa,结果为空 因为最少是0次{n,}?: 至少匹配n次,尽可能少的匹配
如: a{2,6}? 匹配aaaaaa, 匹配到aa贪婪模式
贪婪模式在整个表达式匹配成功的前提下,会尽可能多的匹配符合的结果.
4. 子组
捕获子组 (pattern) 和命名
捕获子组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用。 (pattern) 匹配 pattern 并获取匹配到的内容,所获取的内容可以从产生的 Matches 集合得到, 使用 $1...$9 可获取对应分组.
分类
- 普通捕获子组 (pattern)
- 命名捕获子组(?pattern)
捕获编号规则
捕获子组的编号是按照 ( 出现的顺序,从左到右,从 1 开始进行编号的。由外向内,由左向右
- 正则表达式 :
(\d{4})-(\d{2})-(\d{2})使用上面正则来进行日期的匹配:

(\d{4})-(\d{2}-(\d{2}))
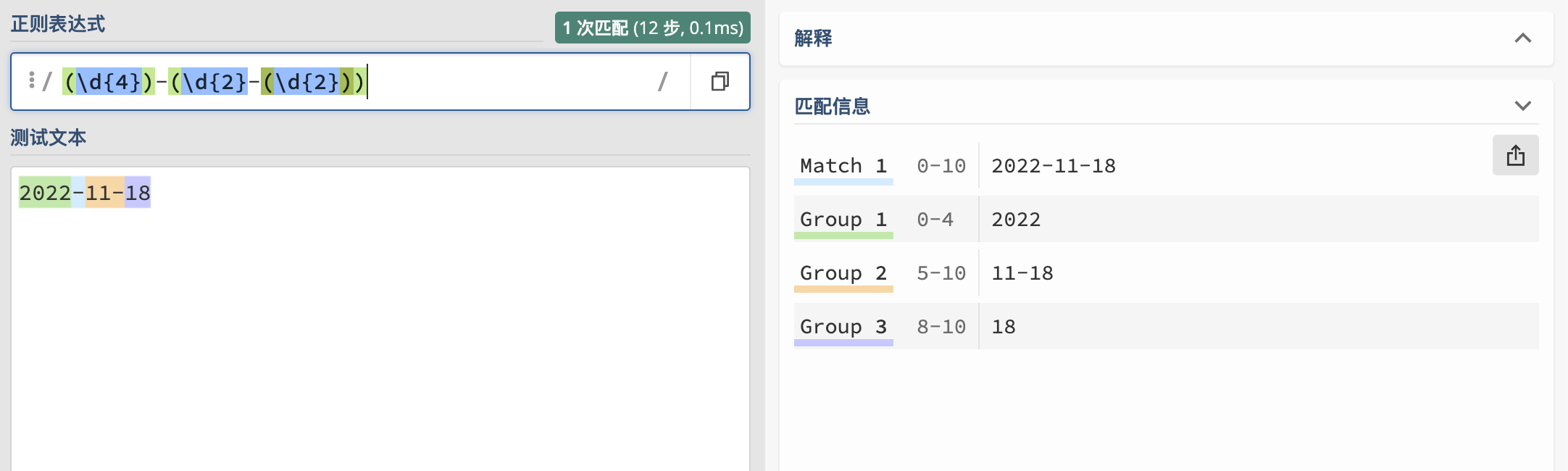
((?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2}))

(?<year>\d{4})-(?<date>\d{2}-(?<day>\d{2}))

(\d{4})-(?<date>\d{2}-(\d{2}))

使用
- 获取标签中的图片地址
<img[^>]*src="(.+?)".*>
非捕获子组 (?:pattern)
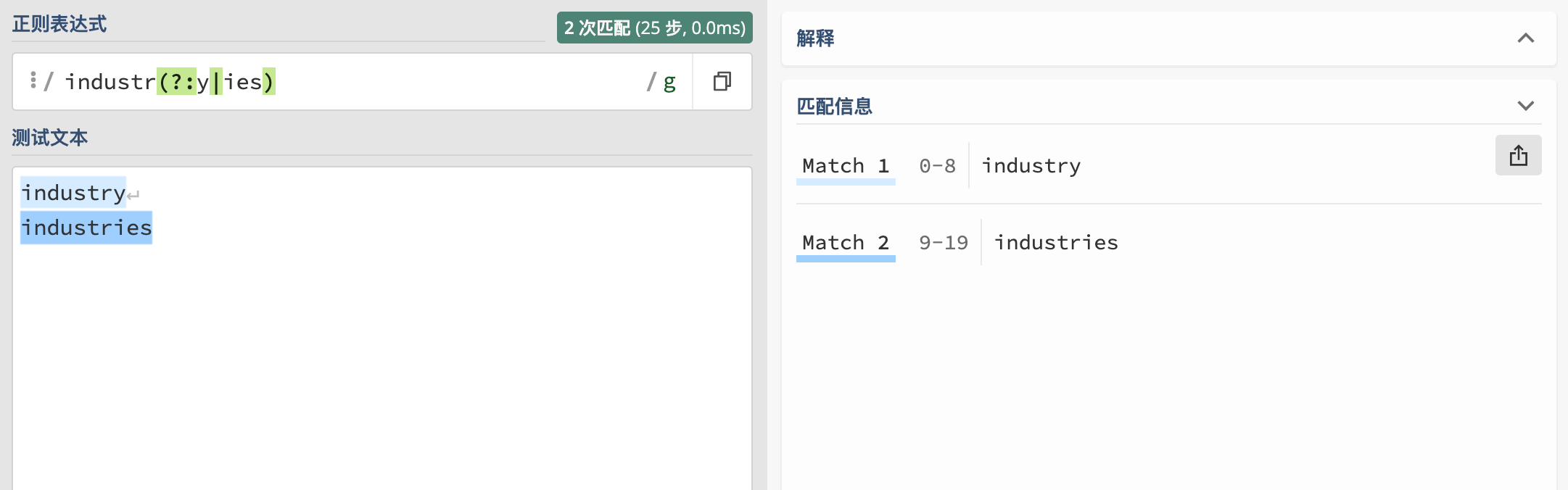
与捕获子组相反,它不捕获文本 ,也不针对组合计进行计数如: 匹配 industry 或者 industries 使用 industr(?:y|ies)写法等价于 industry|industries , 如果捕获则会在工具中展示 Group 信息
(?#comment) 注释
这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读

5. 反向引用
常用在匹配字符串中连续出现的字符, 引用的是前面获取的子表达式。
引用方式使用 \ 加上数字, \1 引用捕获的子组中的第一个子表达式, \2 则是第二个 …依次类推。
- 筛选后面连续出现的n个字符
$regex = '/(.)\1{n-1}/';- 筛选形如 xxabc123xx的字符串
$regex = '/(\w)\1(.*)\1{2}/';6. 环视 / 零宽断言
正向环视
正向预查又称正向环视,分为肯定形式和否定形式两种。查询的为后面是/不是pattern的内容。
肯定形式 (?=pattern) - 后面是pattern
industr(?=y|ies)

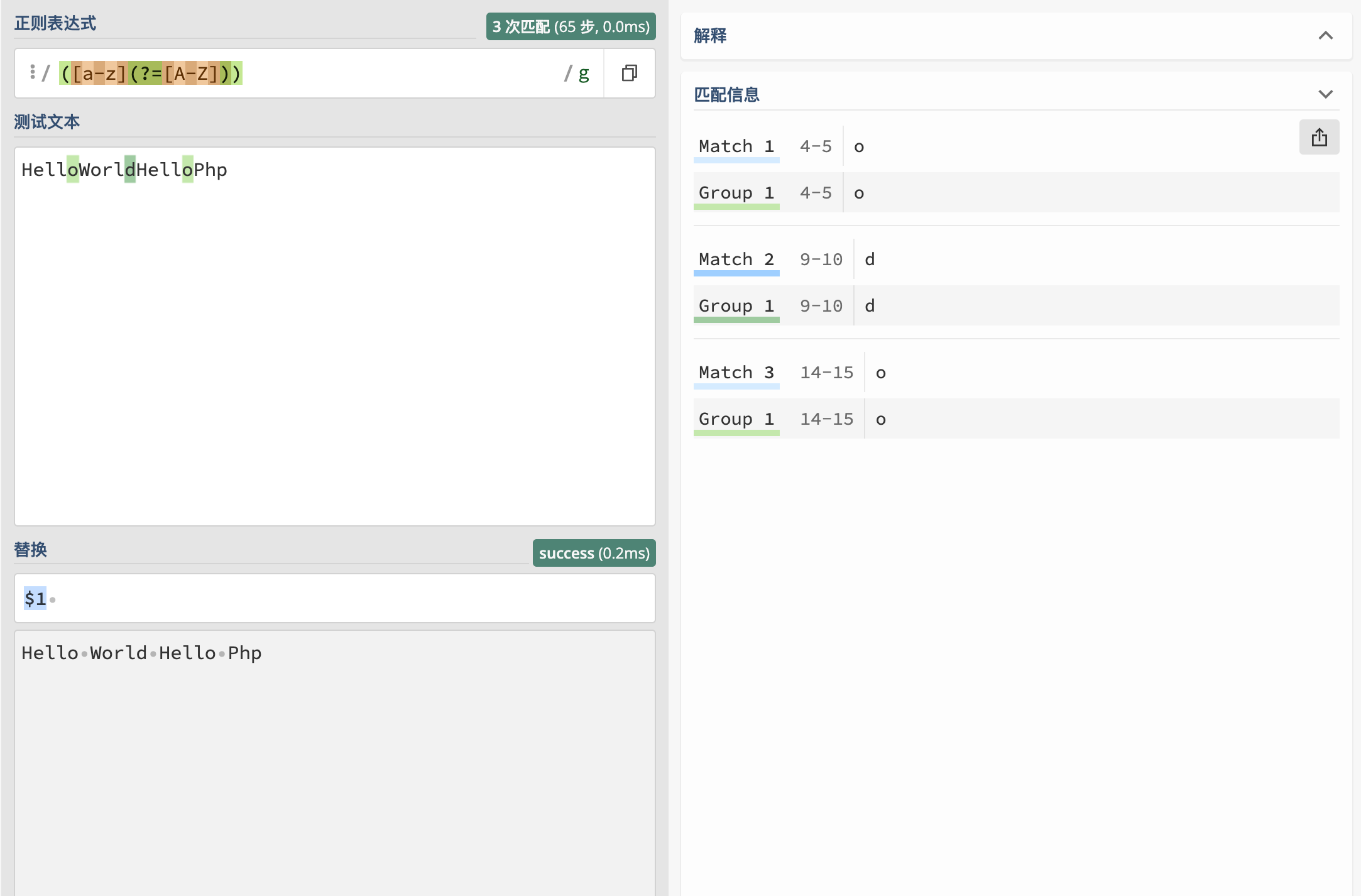
- 将
HelloWorldHelloPhp字符串,按照单词分隔开.变成Hello World Hello Php
否定形式 (?!pattern) - 后面不是pattern
windows (?!\d+)- 搜索后面不是数字的windows

逆向预查
- 逆向预查又称逆向环视,分为肯定形式和否定形式两种。查询的为前面是/不是pattern的内容。
肯定形式 (?<=pattern) - 前面是pattern
(?<=[\x{4e00}-\x{9fa5}])\d+- 查询前面是中文的数字串

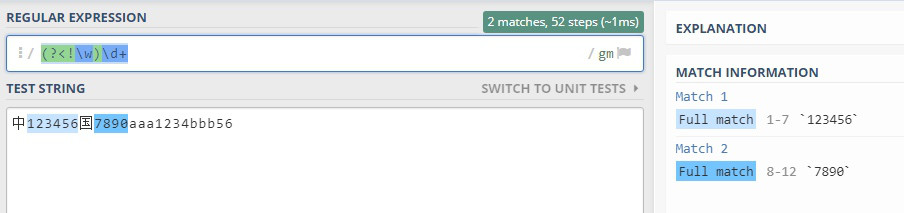
否定形式(?<!pattern) - 前面不是pattern
(?<!\w)\d+- 查询前面不是字母数字下划线的数字串
7. 界定匹配
元字符界定
\Q 抑制所有的元字符进行转义(使用 \ ) 直到遇到 \E 字符,如果你忽略 \E 字符将到最后边的文本被当做普通文本对待

大小写界定
(?i)对其以后的字符开启大小写不敏感
(?-i)对其以后的字符关闭大小写不敏感

扩展
修饰符
摘抄自 : https://regex101.com/
global
匹配全部可匹配结果
multi line
多行模式,此模式下 ^ 和 $ 可以分别匹配行首和行尾
insensitive
不区分大小写
- e
xtended
宽松排列的表达式, 忽略空白字符,可以多行书写,并使用 # 进行注释说明表达式中的大部分空格符变成“忽略自身”的元字符,而#的意思是“忽略该字符及其之后第一个换行符之前的所有字符”,允许空格和注释的正则模式
single line
单行模式,此模式下.能匹配任意字符,包括换行符
unicode
模式字符串被当成UTF-8
Ungreedy
使量词默认为非贪婪模式
Anchored
Anchor to start of pattern, or at the end of the most recent match
Jchanged
允许子模式重复命名,如: (?<name>N1)(?<name>N2)
Dollar end only
$ 字符仅匹配目标字符串的结尾;没有此选项时,如果最后一个字符是换行符的话$字符也能匹配。
补充
[e|a]和(e|a)
这里第一个 | 是可以匹配的,第二个括号可以看做是元字符. (a|e) 看做是一个 e 或者 a 的表达式
- 匹配汉字 : 记住一个范围
4e00 - 9fa5在js和PHP匹配汉字的写法不同:
$regex = '/[\x{4e00}-\x{9fa5}]/u';var regex = '/[\u4e00-\u9fa5]/';- 各种正则工具
grep = global regular expression print
posix = portable operating system interface
preg = perl regular expression
ereg = extended regular expression
- 匹配原理
1.优先选择最左端的匹配结果2.标准量词是匹配优先的 +,*,?,{3,7}
其他未竟讨论项目
| 代码/语法 | 说明 |
| \a | 报警字符(打印它的效果是电脑嘀一声) |
| \b | 通常是单词分界位置,但如果在字符类里使用代表退格 |
| \e | Escape |
| \0nn | ASCII代码中八进制代码为nn的字符 |
| \xnn | ASCII代码中十六进制代码为nn的字符 |
| \unnnn | Unicode代码中十六进制代码为nnnn的字符 |
| \cN | ASCII控制字符。比如\cC代表Ctrl+C |
| \A | 字符串开头(类似^,但不受处理多行选项的影响) |
| \Z | 字符串结尾或行尾(不受处理多行选项的影响) |
| \z | 字符串结尾(类似$,但不受处理多行选项的影响) |
| \G | 当前搜索的开头 |
| \p{name} | Unicode中命名为name的字符类,例如\p{IsGreek} |
| (?>exp) | 贪婪子表达式 |
| (? | 平衡组 |
| (?im-nsx:exp) | 在子表达式exp中改变处理选项 |
| (?im-nsx) | 为表达式后面的部分改变处理选项 |
| (?(exp)yes|no) | 把exp当作零宽正向先行断言,如果在这个位置能匹配,使用yes作为此组的表达式;否则使用no |
| (?(exp)yes) | 同上,只是使用空表达式作为no |
| (?(name)yes|no) | 如果命名为name的组捕获到了内容,使用yes作为表达式;否则使用no |
| (?(name)yes) | 同上,只是使用空表达式作为no |